
NB – this question was first posted on Quora in 2010
The fact that this question is as relevant in 2019 as it was in 2010 tells us something, does it not?
I think we can throw out the “we just need more time” plea. Francis Collins, leader of the human genome initiative and now director of the NIH, asserted that, thanks to genomics, in “…15 or 20 years, you will see a complete transformation in therapeutic medicine.” That was in 2000.
Genomics has failed to discover new medicines because 1) environment is more important than genes; 2) the action of genes is chaotic; and 3) biochemistry got there first.
Decades of twin studies show that the heritability of most diseases is low. For the leading killers (heart disease and cancer) it is 5–20%. And “heritability” includes more than genes—you also inherit things like food preferences and likelihood of smoking from your parents. Sophisticated genome-wide association studies show that even hundreds of “disease-causing” gene variants collectively account for only a tiny fraction of disease risk.
The reason why there is so little straight-line causality between genes and disease is because of the chaotic nature of gene effects. Collins (and me and every other biologist) learned about genetics using the paradigms outlined by Beadle and Tatum and Jacob and Monod: elegant schemes in which simple diagrams leading from gene to effect could be drawn, schemes which resemble nothing so much as a mid-century assembly line, or perhaps a more modern diagram of information flow in a computer program:
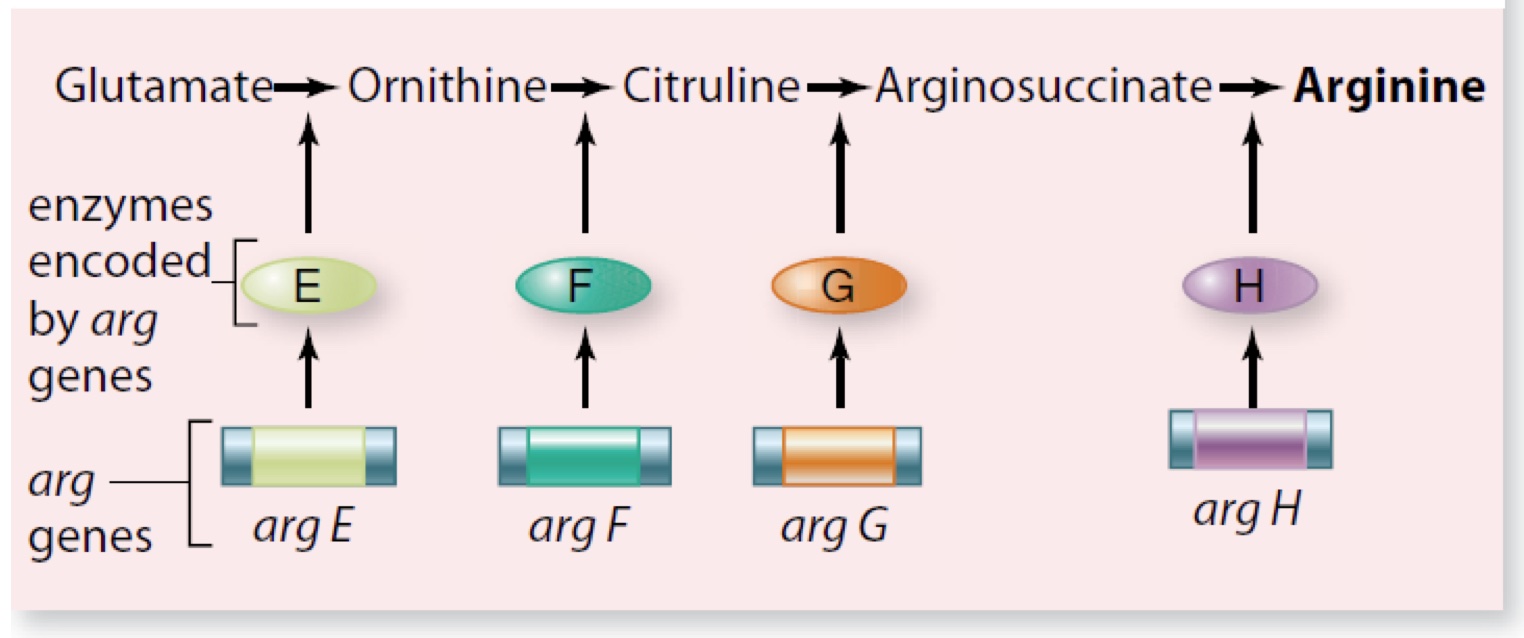

But gene networks for things we actually care about, like tissue development, look like this:

The funny thing about all this complexity and chaos is that it leads to remarkably stable systems, ones that are tuned to use noise and are both responsive to environmental signals yet difficult to perturb. These gene networks aren’t thrown into confusion when interacting with a new variant; they simply adjust and adapt and carry on with the one project that genes are actually “for”: making more copies of themselves.
What Collins and others were imagining in 2000 was that genomics would identify a few variants that cause disease; the proteins produced by these genes would then become targets for drug development; new medicines would result. We would also understand the biology of disease better, and this, in addition to statistical associations, would also yield more drug targets.
That makes sense; it is an elegant and beautiful vision. Call it the “keys to the kingdom” approach. But what if the kingdom has largely been looted? What good are the keys? What if there are only a finite number of drug targets, and the drones slaving away in the fields have already found most of the best ones already?
Good drug targets have big effects. They can be identified by a variety of means: excesses or deficits in diseased tissues; variations in physical properties; their position along metabolic pathways; heritable defects that can be identified by Mendelian genetics or induced by genetic engineering technologies.
Starting at the level of molecules, asking questions like “what is present in a healthy pancreas but lacking in a diabetic one?” is not necessarily the most elegant method of discovering drug targets. It often requires a lot of drudgery, like mincing up tissues and running them over columns and adding different fractions back to cells or organs or animals. Or randomly screening millions of compounds to find one that has a therapeutic effect. You can figure out the target later.
It’s not elegant or efficient. But do it long enough and hard enough—and drug companies have plenty of cash to do both—and you will find plenty of drug targets. Maybe even most of them: there are only 19,000 protein-coding genes (we know this thanks to genomics) and maybe 10% of them are involved in diseases and are druggable. That’s a big number, but not that big. Most validated drug targets fall into just a few functional classes:

From How Many Drug Targets Are There?
This paper estimates that 1587 FDA-approved drugs act on 667 human genome-derived products. If there are indeed only a couple thousand good drug targets, we’d expect to see the rate of discovery of new ones slowing down:

And we do. The vast majority of drug targets were discovered before 1990. The genomic era (post-2000) has seen steady or declining rates of new target discovery, despite vastly better technology and well-funded efforts. The simplest explanation here is that most good drug targets have already been found.
If genomics had been invented in 1940, I don’t doubt that it would have enabled the discovery of hundreds of new drugs. Six decades of biochemistry just left little for genomics to discover. Oops.
1 thought on “Why has genomics been so unsuccessful in the discovery of new medicines?”